data-lakehouse-iceberg-trino-spark
|
This demo shows a data workload with real-world data volumes and uses significant resources to ensure acceptable response times. It will likely not run on your workstation. There is also the smaller trino-iceberg demo focusing on the abilities a lakehouse using Apache Iceberg offers.
The |
|
This demo only runs in the |
Install this demo on an existing Kubernetes cluster:
$ stackablectl demo install data-lakehouse-iceberg-trino-sparkSystem requirements
The demo was developed and tested on a kubernetes cluster with about 12 nodes (4 cores with hyperthreading/SMT, 20GiB RAM and 30GB HDD). Instance types that loosely correspond to this on the Hyperscalers are:
-
Google:
e2-standard-8 -
Azure:
Standard_D4_v2 -
AWS:
m5.2xlarge
In addition to these nodes the operators will request multiple persistent volumes with a total capacity of about 300Gi.
Overview
This demo will
-
Install the required Stackable operators.
-
Spin up the following data products:
-
Trino: A fast distributed SQL query engine for big data analytics that helps you explore your data universe. This demo uses it to enable SQL access to the data.
-
Apache Spark: A multi-language engine for executing data engineering, data science, and machine learning. This demo uses it to stream data from Kafka into the lakehouse.
-
MinIO: S3 compatible object store. This demo uses it as persistent storage to store all the data used
-
Apache Kafka: A distributed event streaming platform for high-performance data pipelines, streaming analytics and data integration. This demo uses it as an event streaming platform to stream the data in near real-time.
-
Apache NiFi: An easy-to-use, robust system to process and distribute data. This demo uses it to fetch multiple online real-time data sources and ingest it into Kafka.
-
Apache Hive metastore: A service that stores metadata related to Apache Hive and other services. This demo uses it as metadata storage for Trino and Spark.
-
Open policy agent (OPA): An open-source, general-purpose policy engine unifying policy enforcement across the stack. This demo uses it as the authorizer for Trino, which decides which user can query which data.
-
Apache Superset: A modern data exploration and visualization platform. This demo utilizes Superset to retrieve data from Trino via SQL queries and build dashboards on top of that data.
-
-
Copy multiple data sources in CSV and Parquet format into the S3 staging area.
-
Let Trino copy the data from the staging area into the lakehouse area. During the copy, transformations such as validating, casting, parsing timestamps and enriching the data by joining lookup tables are done.
-
Simultaneously, start a NiFi workflow, which fetches datasets in real-time via the internet and ingests the data as JSON records into Kafka.
-
Spark structured streaming job is started, which streams the data out of Kafka into the lakehouse.
-
Create Superset dashboards for visualization of the different datasets.
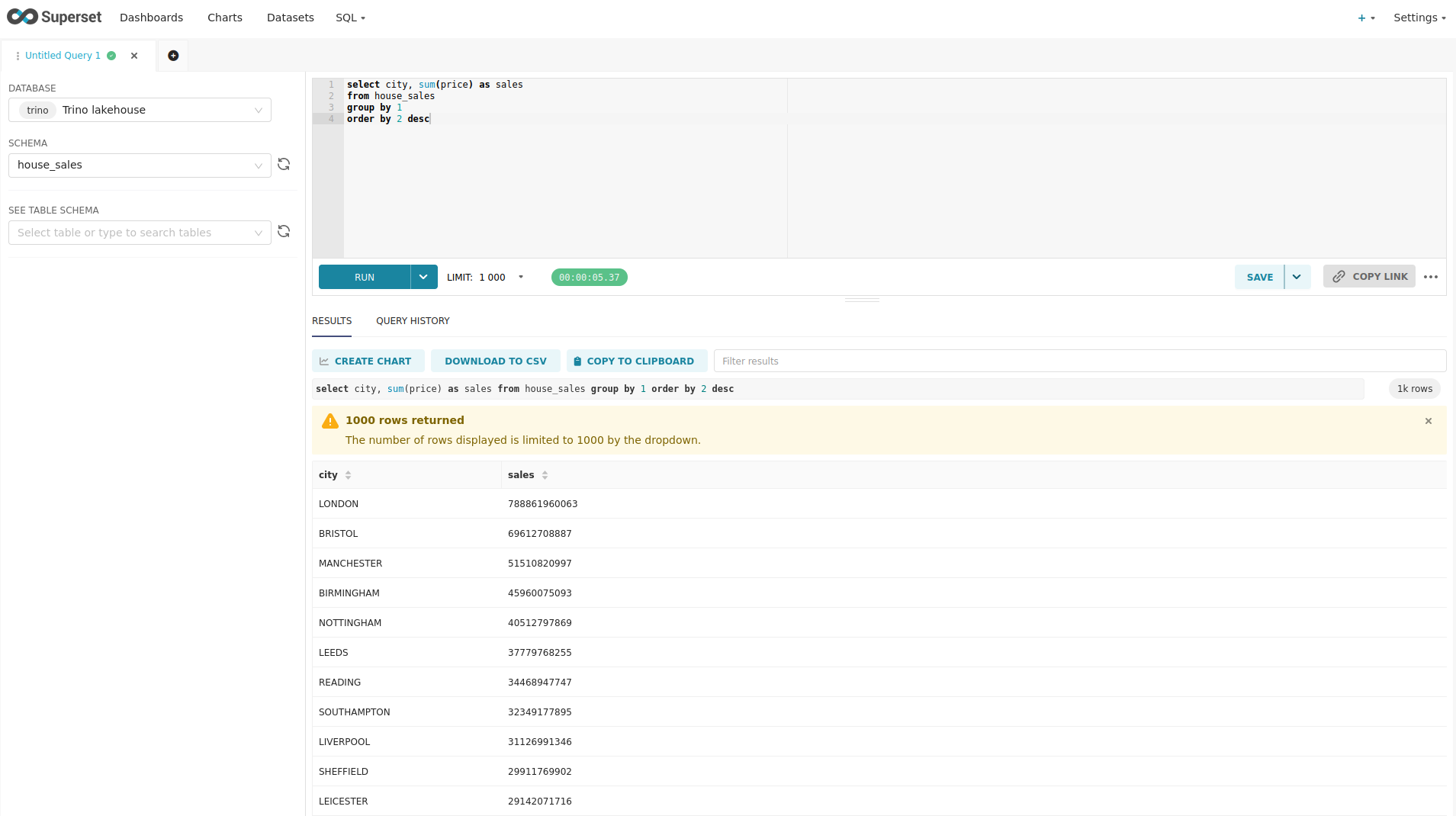
You can see the deployed products and their relationship in the following diagram:
Apache Iceberg
As Apache Iceberg states on their website:
Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to compute engines including Spark, Trino, PrestoDB, Flink, Hive and Impala using a high-performance table format that works just like a SQL table.
This demo uses Iceberg, which plays nicely with object storage and has integrations for Trino and Spark. It also provides the following benefits among other things, instead of putting Apache Parquet files directly into S3 using the Hive connector:
-
Standardized table storage: Using this standardized specification, multiple tools such as Trino, Spark and Flink can read and write Iceberg tables.
-
Versioned tables with snapshots, time travel and rollback mechanisms
-
Row level updates and deletes: Deletes will be written as separate files for best performance and compacted with the below-mentioned mechanism.
-
Built-in compaction: Running table maintenance functions such as compacting smaller files (including deleted files) into larger files for best query performance is recommended. Iceberg offers out-of-the-box tools for this.
-
Hidden partitioning: Imagine you have a table
sales (day varchar, ts timestamp)partitioned byday. Lots of times, users would run a statement such asselect count(*) where ts > now() - interval 1 day, resulting in a full table scan as the partition columndaywas not filtered in the query. Iceberg resolves this problem by using hidden partitions. In Iceberg, your table would look likesales (ts timestamp) with (partitioning = ARRAY['day(ts)']). The columndayis not needed anymore, and the queryselect count(\*) where ts > now() - interval 1 daywould use partition pruning as expected to read only one the partitions from today and yesterday. -
Branching and tagging: Iceberg enables git-like semantics on your lakehouse. You can create tags pointing to a specific snapshot of your data and branches. For details, read this excellent blog post. Currently, this is only supported in Spark. Trino is working on support.
If you want to read more about the motivation and the working principles of Iceberg, have a read on their website or GitHub repository.
List the deployed Stackable services
To list the installed installed Stackable services run the following command:
$ stackablectl stacklet list
┌───────────┬───────────────┬───────────┬────────────────────────────────────────────────────┬─────────────────────────────────┐
│ PRODUCT ┆ NAME ┆ NAMESPACE ┆ ENDPOINTS ┆ CONDITIONS │
╞═══════════╪═══════════════╪═══════════╪════════════════════════════════════════════════════╪═════════════════════════════════╡
│ hive ┆ hive ┆ default ┆ ┆ Available, Reconciling, Running │
├╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ hive ┆ hive-iceberg ┆ default ┆ ┆ Available, Reconciling, Running │
├╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ kafka ┆ kafka ┆ default ┆ metrics 217.160.99.235:31148 ┆ Available, Reconciling, Running │
│ ┆ ┆ ┆ kafka-tls 217.160.99.235:31202 ┆ │
├╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ nifi ┆ nifi ┆ default ┆ https https://5.250.180.98:31825 ┆ Available, Reconciling, Running │
├╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ opa ┆ opa ┆ default ┆ ┆ Available, Reconciling, Running │
├╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ superset ┆ superset ┆ default ┆ external-http http://87.106.122.58:32452 ┆ Available, Reconciling, Running │
├╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ trino ┆ trino ┆ default ┆ coordinator-metrics 212.227.194.245:31920 ┆ Available, Reconciling, Running │
│ ┆ ┆ ┆ coordinator-https https://212.227.194.245:30841 ┆ │
├╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ zookeeper ┆ zookeeper ┆ default ┆ ┆ Available, Reconciling, Running │
├╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ minio ┆ minio-console ┆ default ┆ http http://217.160.99.235:30238 ┆ │
└───────────┴───────────────┴───────────┴────────────────────────────────────────────────────┴─────────────────────────────────┘|
When a product instance has not finished starting yet, the service will have no endpoint. Depending on your internet connectivity, creating all the product instances might take considerable time. A warning might be shown if the product is not ready yet. |
MinIO
Listing Buckets
The S3 provided by MinIO is used as persistent storage to store all the data used. Open the minio endpoint
http retrieved by the stackablectl stacklet list command in your browser (http://217.160.99.235:30238 in
this case).

Log in with the username admin and password adminadmin.
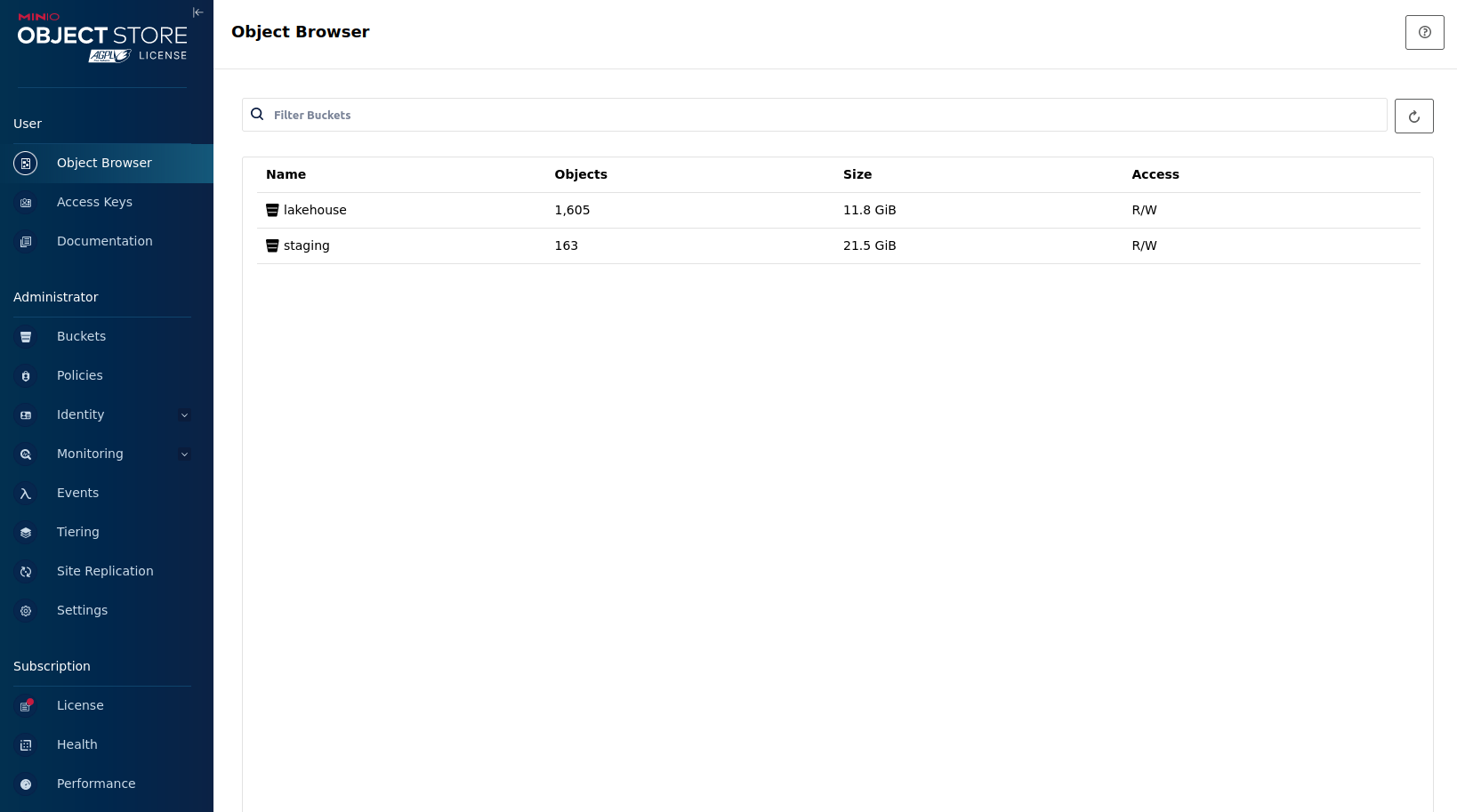
Here, you can see the two buckets contained in the S3:
-
staging: The demo loads static datasets into this area. It is stored in different formats, such as CSV and Parquet. It does contain actual data tables as well as lookup tables. -
lakehouse: This bucket is where the cleaned and aggregated data resides. The data is stored in the Apache Iceberg table format.
Inspecting Lakehouse
Click on the bucket lakehouse.
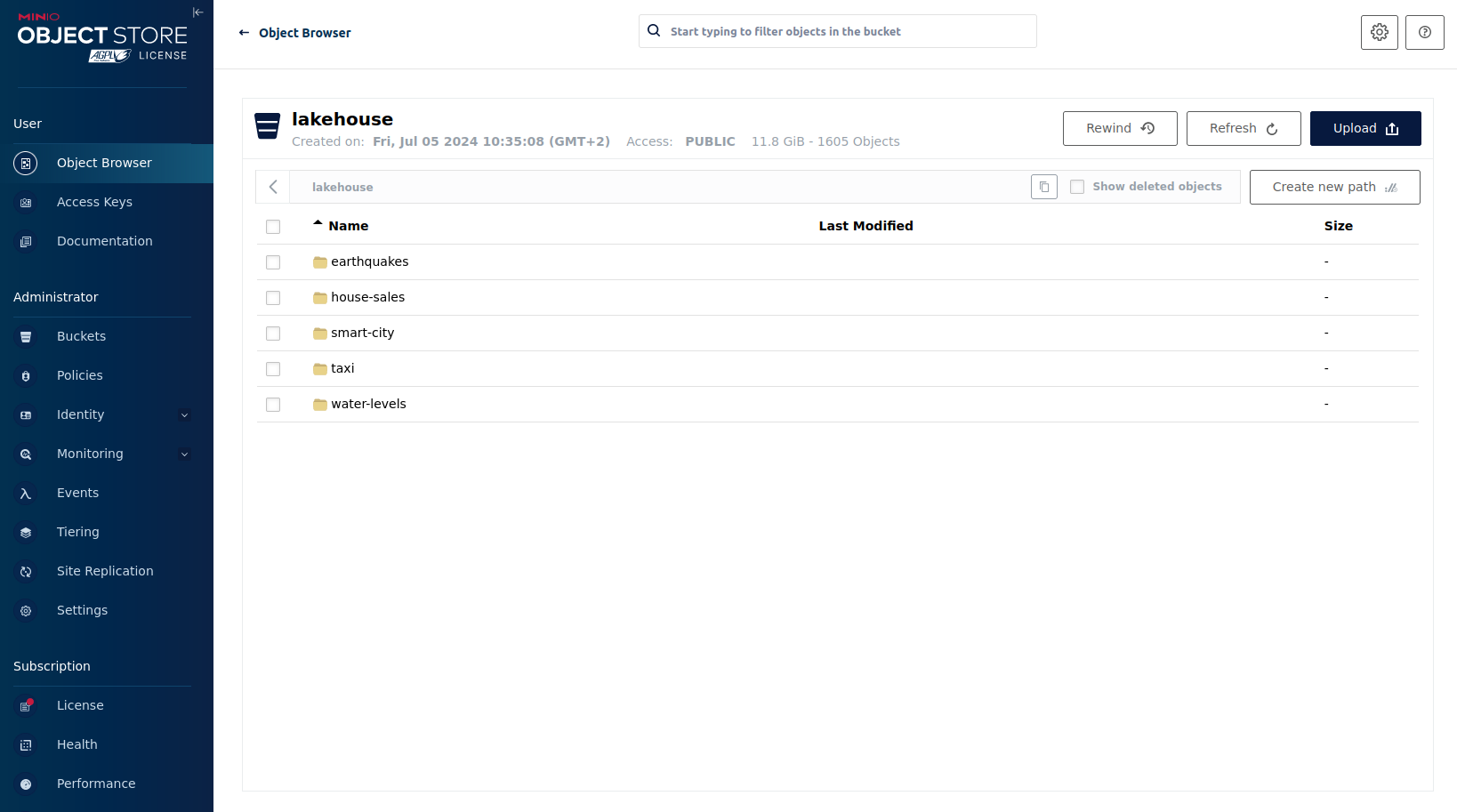
Multiple folders (called prefixes in S3), each containing a different dataset, are displayed. First, select the folder
house-sales, then the folder starting with house-sales-*, and lastly, the folder named data.
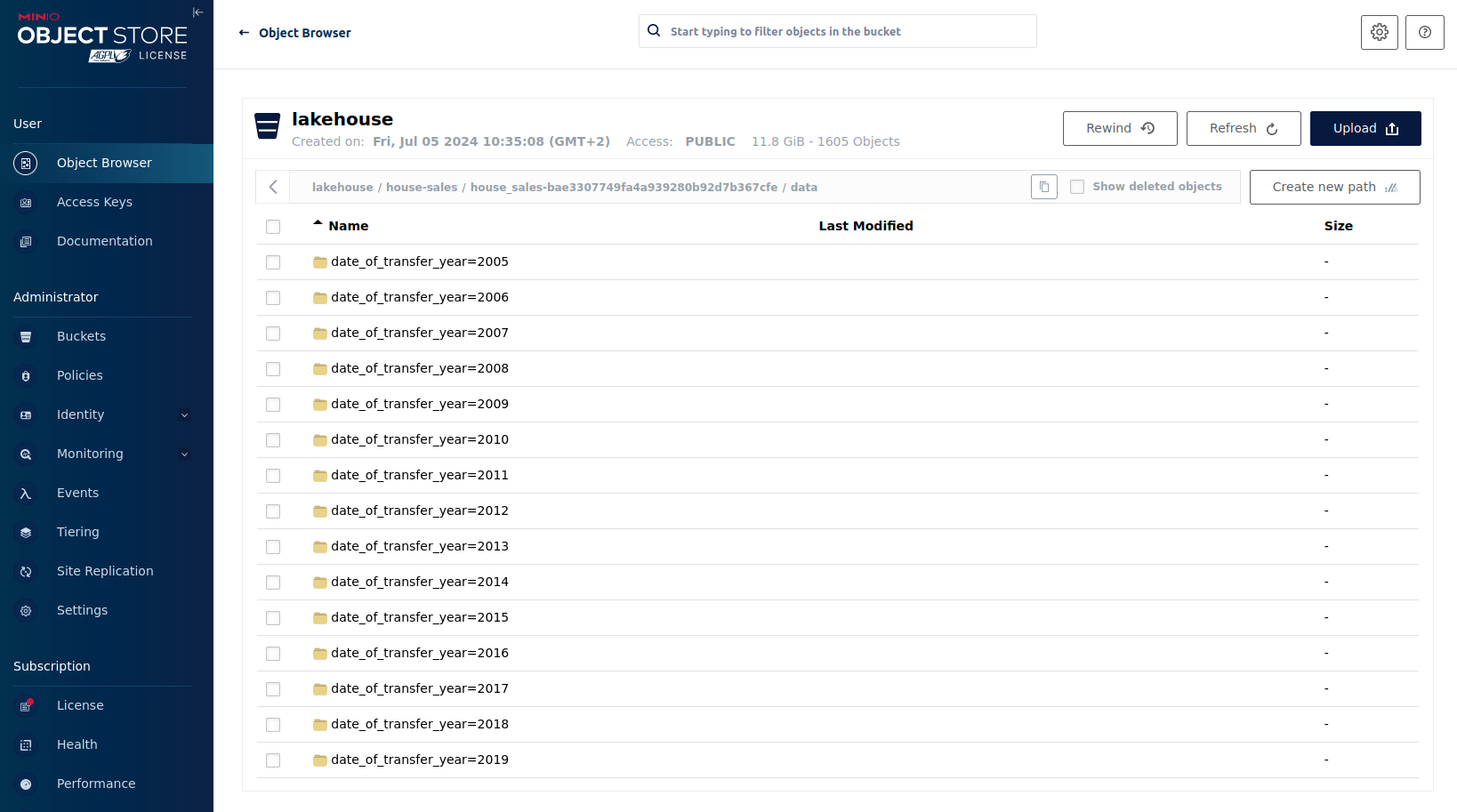
As you can see, the table house-sales is partitioned by year. Go ahead and click on any folder.
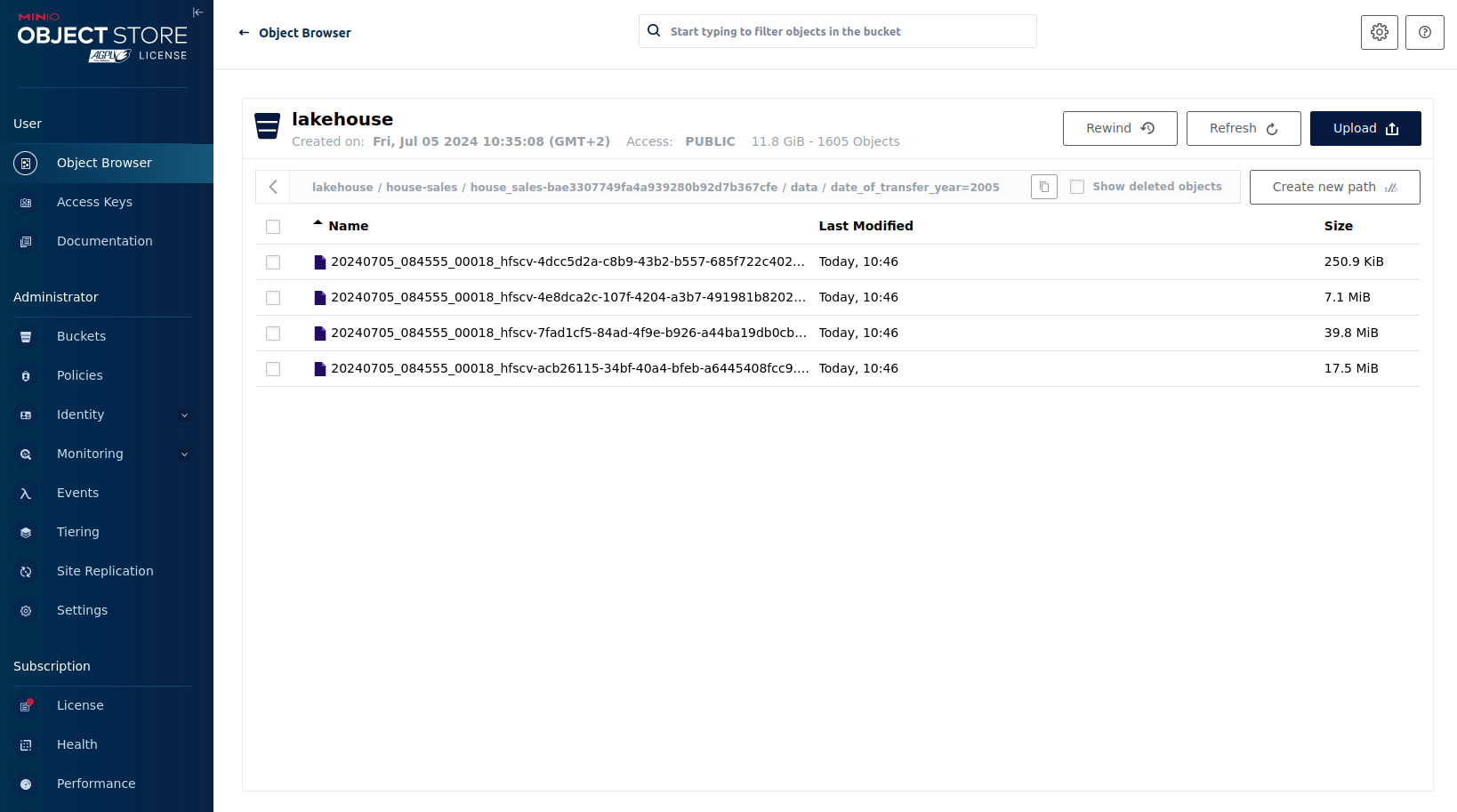
You can see that Trino has data into the selected folder containing all the house sales of that particular year.
NiFi
NiFi is used to fetch multiple data sources from the internet and ingest it into Kafka near-realtime. Some of these sources are statically downloaded (e.g. as CSV), and others are fetched dynamically via APIs endpoints, including:
-
Water level measurements in Germany (real-time)
-
Shared bikes in Germany (real-time)
-
House sales in the UK (static)
-
Registered earthquakes worldwide (static)
-
E-charging stations in Germany (static)
-
NewYork taxi data (static)
View ingestion jobs
You can have a look at the ingestion job running in NiFi by opening the NiFi endpoint https from your
stackablectl stacklet list command output (https://5.250.180.98:31825 in this case).
|
Suppose you get a warning regarding the self-signed certificate generated by the Secret Operator (e.g. Warning: Potential Security Risk Ahead). In that case, you must tell your browser to trust the website and continue. |
Log in with the username admin and password adminadmin.
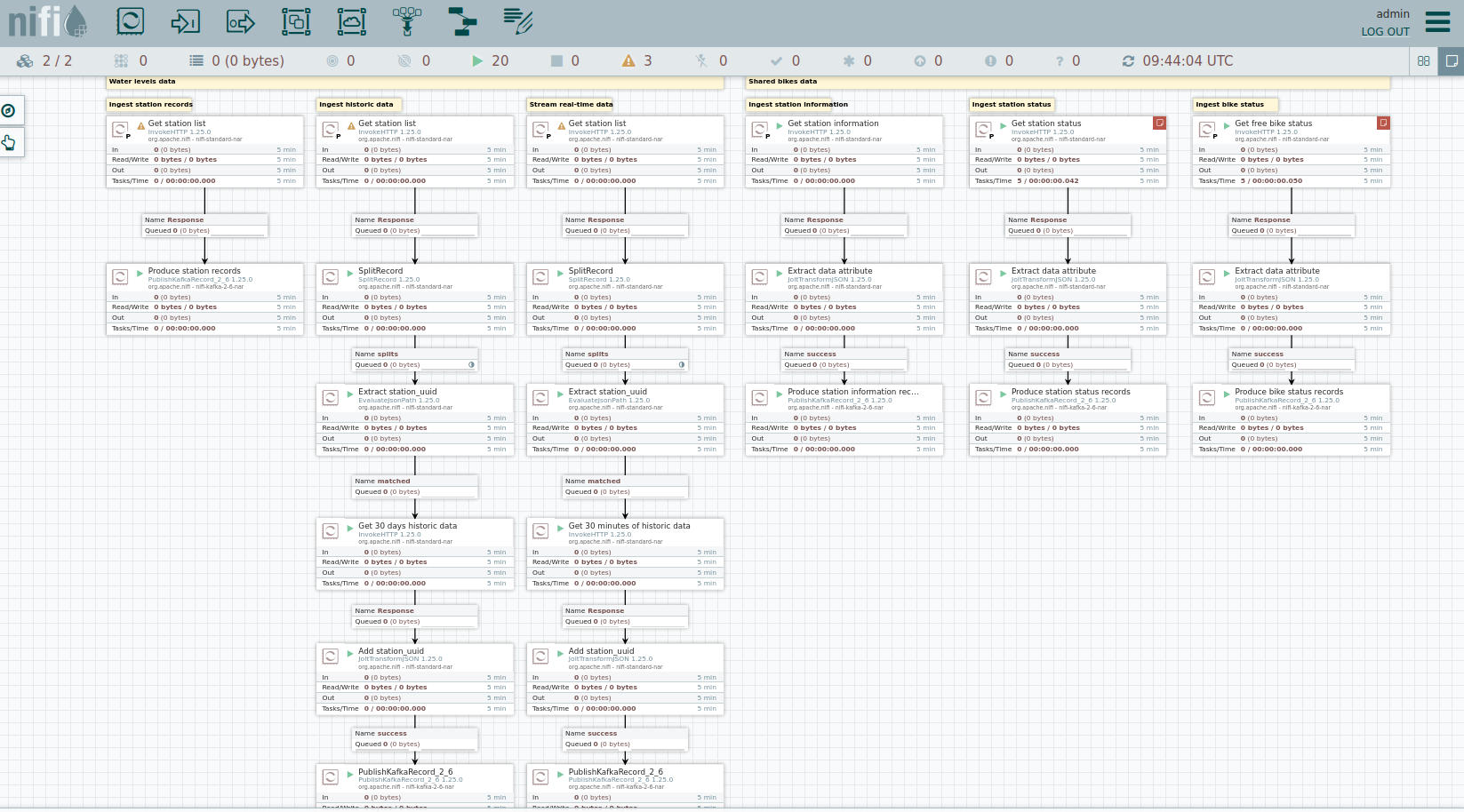
As you can see, the NiFi workflow consists of lots of components. You can zoom in by using your mouse and mouse wheel. On the left side are three strands, that
-
Fetch the list of known water-level stations and ingest them into Kafka.
-
Fetch measurements of the last 30 days for every measuring station and ingest them into Kafka.
-
Continuously run a loop fetching the measurements for every measuring station and ingesting them into Kafka.
On the right side are three strands, that
-
Fetch the current shared bike station information
-
Fetch the current shared bike station status
-
Fetch the current shared bike status
For details on the NiFi workflow ingesting water-level data, read the nifi-kafka-druid-water-level-data documentation on NiFi.
Spark
Spark Structured Streaming is used to stream data from Kafka into the lakehouse.
Accessing the web interface
To have access to the Spark web interface you need to run the following command to forward port 4040 to your local machine.
$ kubectl port-forward $(kubectl get pod -o name | grep 'spark-ingest-into-lakehouse-.*-driver') 4040Afterwards you can access the web interface on http://localhost:4040.
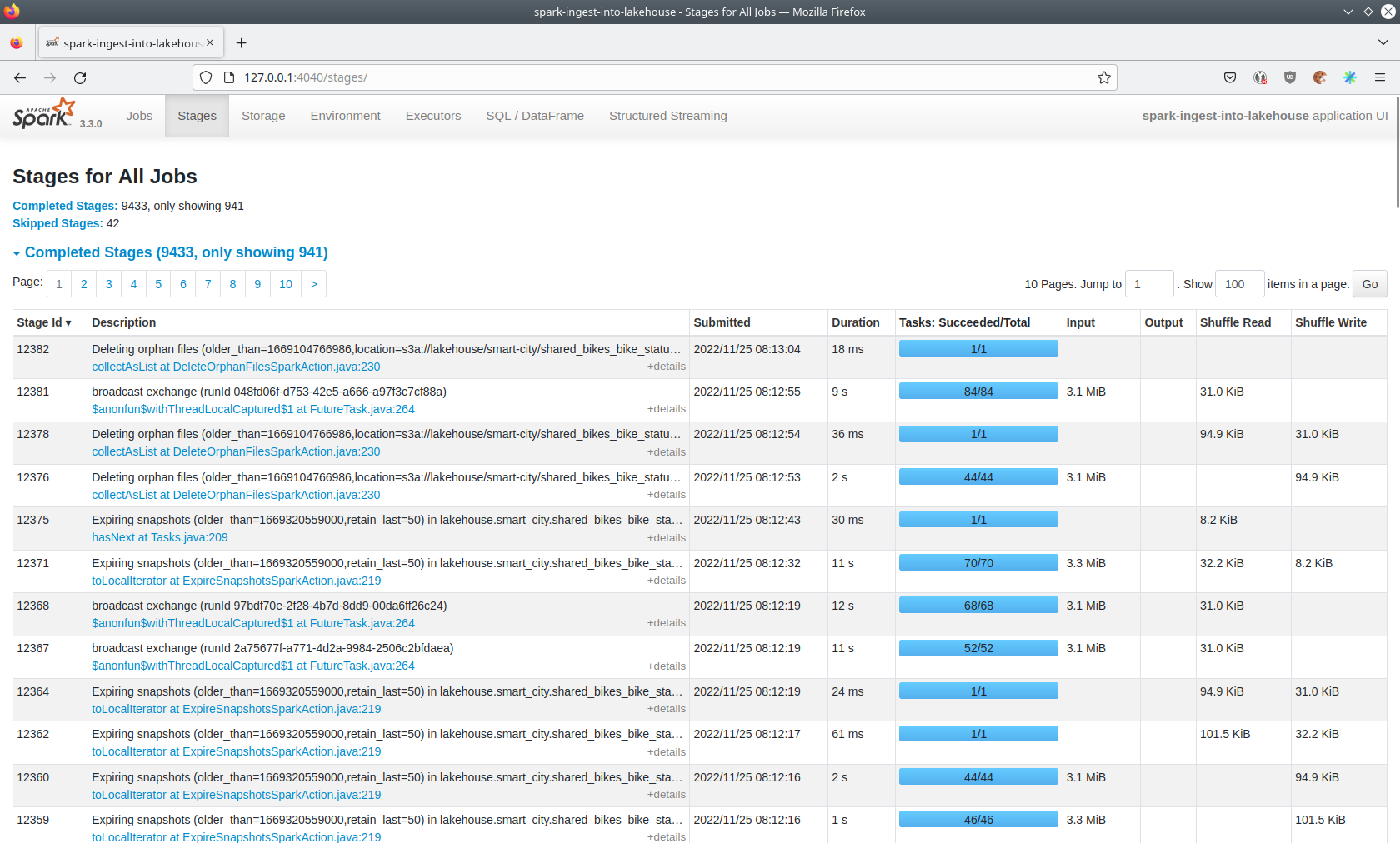
Listing the running Structured Streaming jobs
The UI displays the last job runs.
Each running Structured Streaming job creates lots of Spark jobs internally.
Click on the Structured Streaming tab to see the running streaming jobs.
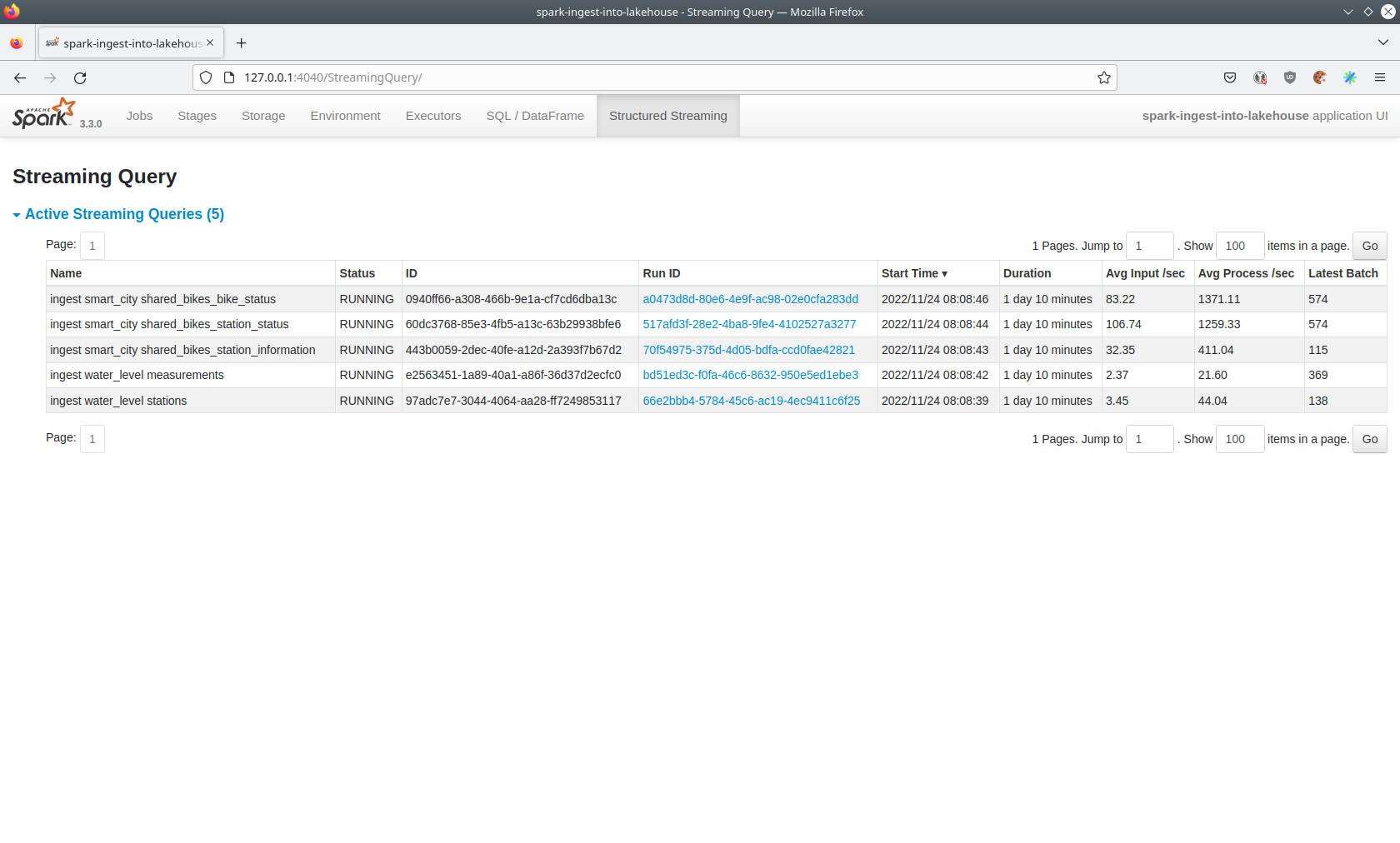
Five streaming jobs are currently running.
You can also click on a streaming job to get more details.
For the job ingest smart_city shared_bikes_station_status click, on the Run ID highlighted in blue to open them up.
How the Structured Streaming jobs work
The demo has started all the running streaming jobs. Look at the demo code to see the actual code submitted to Spark.
This document will explain one specific ingestion job - ingest water_level measurements.
The streaming job is written in Python using pyspark.
First off, the schema used to parse the JSON coming from Kafka is defined.
Nested structures or arrays are supported as well.
The schema differs from job to job.
schema = StructType([ \
StructField("station_uuid", StringType(), True), \
StructField("timestamp", TimestampType(), True), \
StructField("value", FloatType(), True), \
])Afterwards, a streaming read from Kafka is started. It reads from our Kafka at kafka:9093 with the topic water_levels_measurements.
When starting up, the job will ready all the existing messages in Kafka (read from earliest) and will process 50000000 records as a maximum in a single batch.
As Kafka has retention set up, Kafka records might alter out of the topic before Spark has read the records, which can be the case when the Spark application wasn’t running or crashed for too long.
In the case of this demo, the streaming job should not error out.
For a production job, failOnDataLoss should be set to true so that missing data does not go unnoticed - and Kafka offsets need to be adjusted manually, as well as some post-loading of data.
Note: The following Python snippets belong to a single Python statement but are split into separate blocks for better explanation.
spark \
.readStream \
.format("kafka") \
.options(**kafkaOptions) \
.option("subscribe", "water_levels_measurements") \
.option("startingOffsets", "earliest") \
.option("maxOffsetsPerTrigger", 50000000) \
.option("failOnDataLoss", "false") \
.load() \So far we have a readStream reading from Kafka. Records on Kafka are simply a byte-stream, so they must be converted to strings and the json needs to be parsed.
.selectExpr("cast(key as string)", "cast(value as string)") \
.withColumn("json", from_json(col("value"), schema)) \Afterwards, we only select the needed fields (coming from JSON).
We are not interested in all the other fields, such as key, value, topic or offset.
The metadata of the Kafka records, such as topic, timestamp, partition and offset, are also available.
Have a look at the Spark streaming documentation on Kafka.
.select("json.station_uuid", "json.timestamp", "json.value") \After all these transformations, we need to specify the sink of the stream, in this case, the Iceberg lakehouse.
We are writing in the iceberg format using the update mode rather than the "normal" append mode.
Spark will aim for a micro-batch every 2 minutes and save its checkpoints (its current offsets on the Kafka topic) in the specified S3 location.
Afterwards, the streaming job will be started by calling .start().
.writeStream \
.queryName("ingest water_level measurements") \
.format("iceberg") \
.foreachBatch(upsertWaterLevelsMeasurements) \
.outputMode("update") \
.trigger(processingTime='2 minutes') \
.option("checkpointLocation", "s3a://lakehouse/water-levels/checkpoints/measurements") \
.start()The Deduplication mechanism
One important part was skipped during the walkthrough:
.foreachBatch(upsertWaterLevelsMeasurements) \upsertWaterLevelsMeasurements is a Python function that describes inserting the records from Kafka into the lakehouse table.
This specific streaming job removes all duplicate records that can occur because of how the PegelOnline API works and gets called.
As we don’t want duplicate rows in our lakehouse tables, we need to filter the duplicates out as follows.
def upsertWaterLevelsMeasurements(microBatchOutputDF, batchId):
microBatchOutputDF.createOrReplaceTempView("waterLevelsMeasurementsUpserts")
microBatchOutputDF._jdf.sparkSession().sql("""
MERGE INTO lakehouse.water_levels.measurements as t
USING (SELECT DISTINCT * FROM waterLevelsMeasurementsUpserts) as u
ON u.station_uuid = t.station_uuid AND u.timestamp = t.timestamp
WHEN NOT MATCHED THEN INSERT *
""")First, the data frame containing the upserts (records from Kafka) will be registered as a temporary view so that they can be accessed via Spark SQL.
Afterwards, the MERGE INTO statement adds the new records to the lakehouse table.
The incoming records are first de-duplicated (using SELECT DISTINCT * FROM waterLevelsMeasurementsUpserts) so that the data from Kafka does not contain duplicates.
Afterwards, the - now duplication-free - records get added to the lakehouse.water_levels.measurements, but only if they still need to be present.
The Upsert mechanism
The MERGE INTO statement can be used for de-duplicating data and updating existing rows in the lakehouse table.
The ingest water_level stations streaming job uses the following MERGE INTO statement:
MERGE INTO lakehouse.water_levels.stations as t
USING
(
SELECT station_uuid, number, short_name, long_name, km, agency, latitude, longitude, water_short_name, water_long_name
FROM waterLevelsStationInformationUpserts
WHERE (station_uuid, kafka_timestamp) IN (SELECT station_uuid, max(kafka_timestamp) FROM waterLevelsStationInformationUpserts GROUP BY station_uuid)
) as u
ON u.station_uuid = t.station_uuid
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *First, the data within a batch is de-deduplicated as well. The record containing the station update with the highest Kafka timestamp is the newest and will be used during Upsert.
If a record for a station (detected by the same station_uuid) already exists, its contents will be updated.
If the station is yet to be discovered, it will be inserted.
The MERGE INTO also supports updating subsets of fields and more complex calculations, e.g. incrementing a counter.
For details, have a look at the Iceberg MERGE INTO documentation.
The Delete mechanism
The MERGE INTO statement can de-duplicate data and update existing lakehouse table rows.
For details have a look at the Iceberg MERGE INTO documentation.
Table maintenance
As mentioned, Iceberg supports out-of-the-box table maintenance such as compaction.
This demo executes some maintenance functions in a rudimentary Python loop with timeouts in between. When running in production, the maintenance can be scheduled using Kubernetes CronJobs or Apache Airflow, which the Stackable Data Platform also supports.
# key: table name
# value: compaction strategy
tables_to_compact = {
"lakehouse.water_levels.stations": "",
"lakehouse.water_levels.measurements": ", strategy => 'sort', sort_order => 'timestamp DESC NULLS LAST,station_uuid ASC NULLS LAST'",
"lakehouse.smart_city.shared_bikes_station_information": "",
"lakehouse.smart_city.shared_bikes_station_status": ", strategy => 'sort', sort_order => 'last_reported DESC NULLS LAST,station_id ASC NULLS LAST'",
"lakehouse.smart_city.shared_bikes_bike_status": "",
}
while True:
expire_before = (datetime.now() - timedelta(hours=12)).strftime("%Y-%m-%d %H:%M:%S")
for table, table_compaction_strategy in tables_to_compact.items():
print(f"[{table}] Expiring snapshots older than 12 hours ({expire_before})")
spark.sql(f"CALL lakehouse.system.expire_snapshots(table => '{table}', older_than => TIMESTAMP '{expire_before}', retain_last => 50, stream_results => true)")
print(f"[{table}] Removing orphaned files")
spark.sql(f"CALL lakehouse.system.remove_orphan_files(table => '{table}')")
print(f"[{table}] Starting compaction")
spark.sql(f"CALL lakehouse.system.rewrite_data_files(table => '{table}'{table_compaction_strategy})")
print(f"[{table}] Finished compaction")
print("All tables compacted. Waiting 25min before scheduling next run...")
time.sleep(25 * 60) # Assuming compaction takes 5 min run every 30 minutesThe scripts have a dictionary of all the tables to run maintenance on. The following procedures are run:
expire_snapshots
Each write/update/delete/upsert/compaction in Iceberg produces a new snapshot while keeping the old data and metadata around for snapshot isolation and time travel. The expire_snapshots procedure can be used to remove older snapshots and their files which are no longer needed.
remove_orphan_files
Used to remove files which are not referenced in any metadata files of an Iceberg table and can thus be considered "orphaned".
rewrite_data_files
Iceberg tracks each data file in a table. More data files leads to more metadata stored in manifest files, and small data files causes an unnecessary amount of metadata and less efficient queries from file open costs. Iceberg can compact data files in parallel using Spark with the rewriteDataFiles action. This will combine small files into larger files to reduce metadata overhead and runtime file open cost.
Some tables will also be sorted during rewrite, have a look at the documentation on rewrite_data_files.
Trino
Trino is used to enable SQL access to the data.
Accessing the web interface
Open up the the Trino endpoint coordinator-https from your stackablectl stacklet list command output
(https://212.227.194.245:30841 in this case).
Log in with the username admin and password adminadmin.
Connect to Trino
Have a look at the trino-operator documentation on how to connect to Trino. This demo recommends to use DBeaver, as Trino consists of many schemas and tables you can explore.
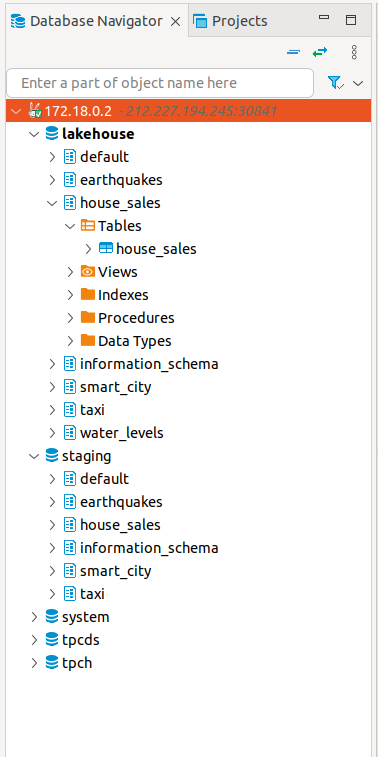
Here you can see all the available Trino catalogs.
-
staging: The staging area containing raw data in various data formats such as CSV or Parquet -
system: Internal catalog to retrieve Trino internals -
tpcds: TPCDS connector providing a set of schemas to support the TPC Benchmark™ DS -
tpch: TPCH connector providing a set of schemas to support the TPC Benchmark™ H -
lakehouse: The lakehouse area containing the enriched and performant accessible data
Superset
Superset provides the ability to execute SQL queries and build dashboards.
Open the Superset endpoint external-http in your browser (http://87.106.122.58:32452 in this case).
Log in with the username admin and password adminadmin.
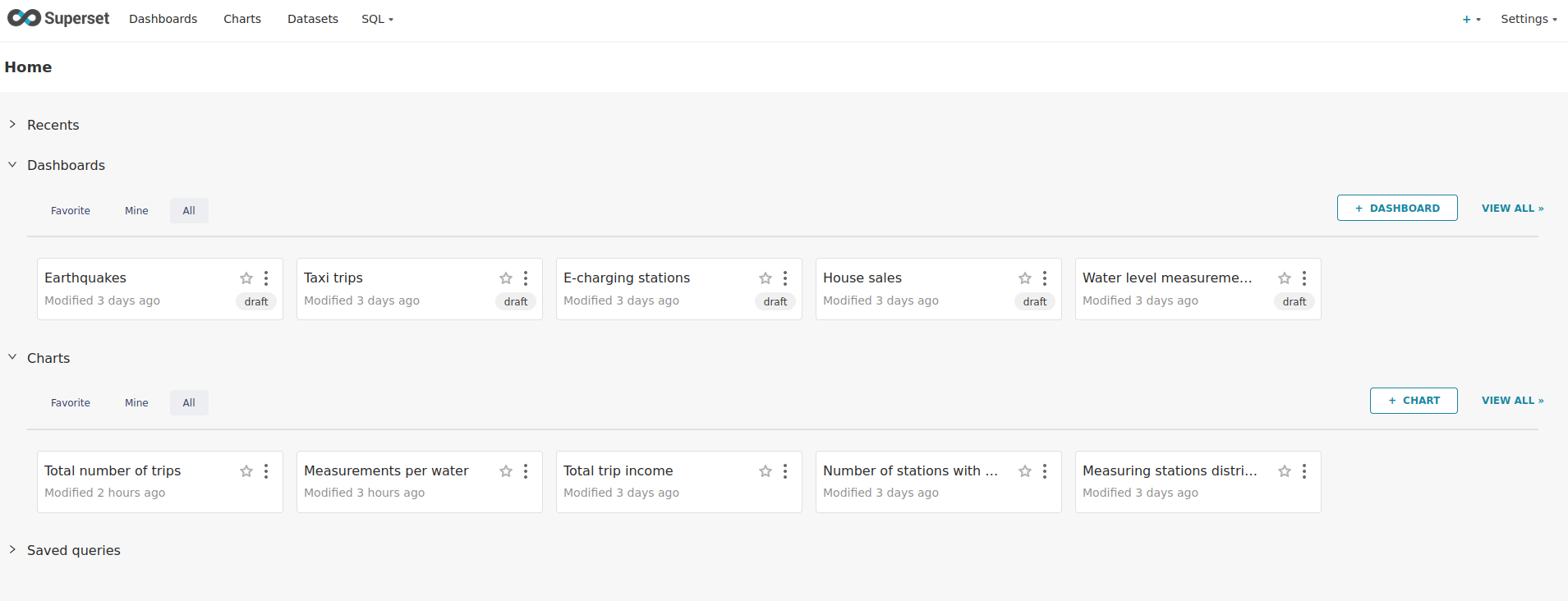
Viewing the Dashboard
The demo has created dashboards to visualize the different data sources.
Select the Dashboards tab at the top to view these dashboards.
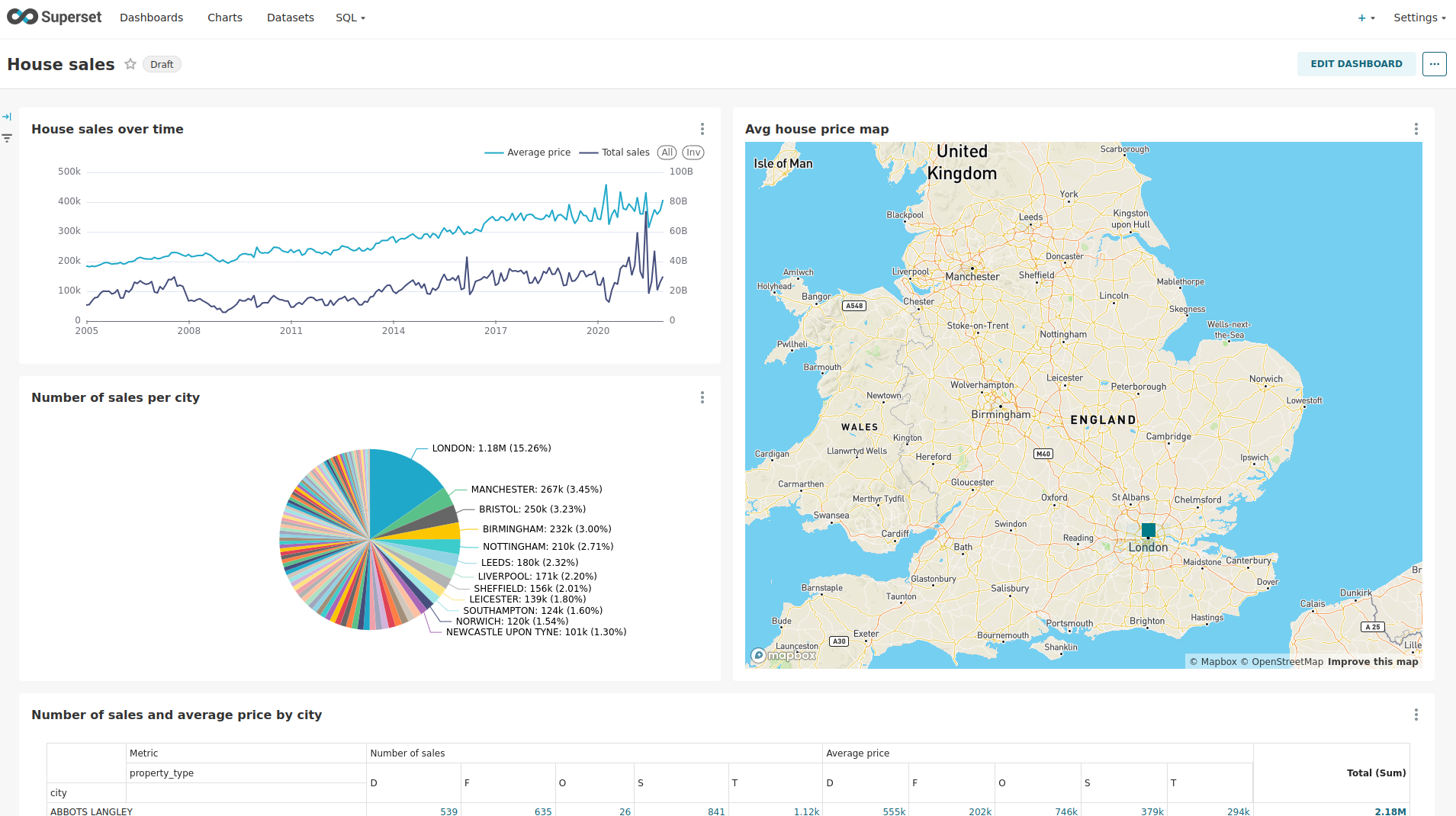
Click on the dashboard called House sales.
It might take some time until the dashboards renders all the included charts.
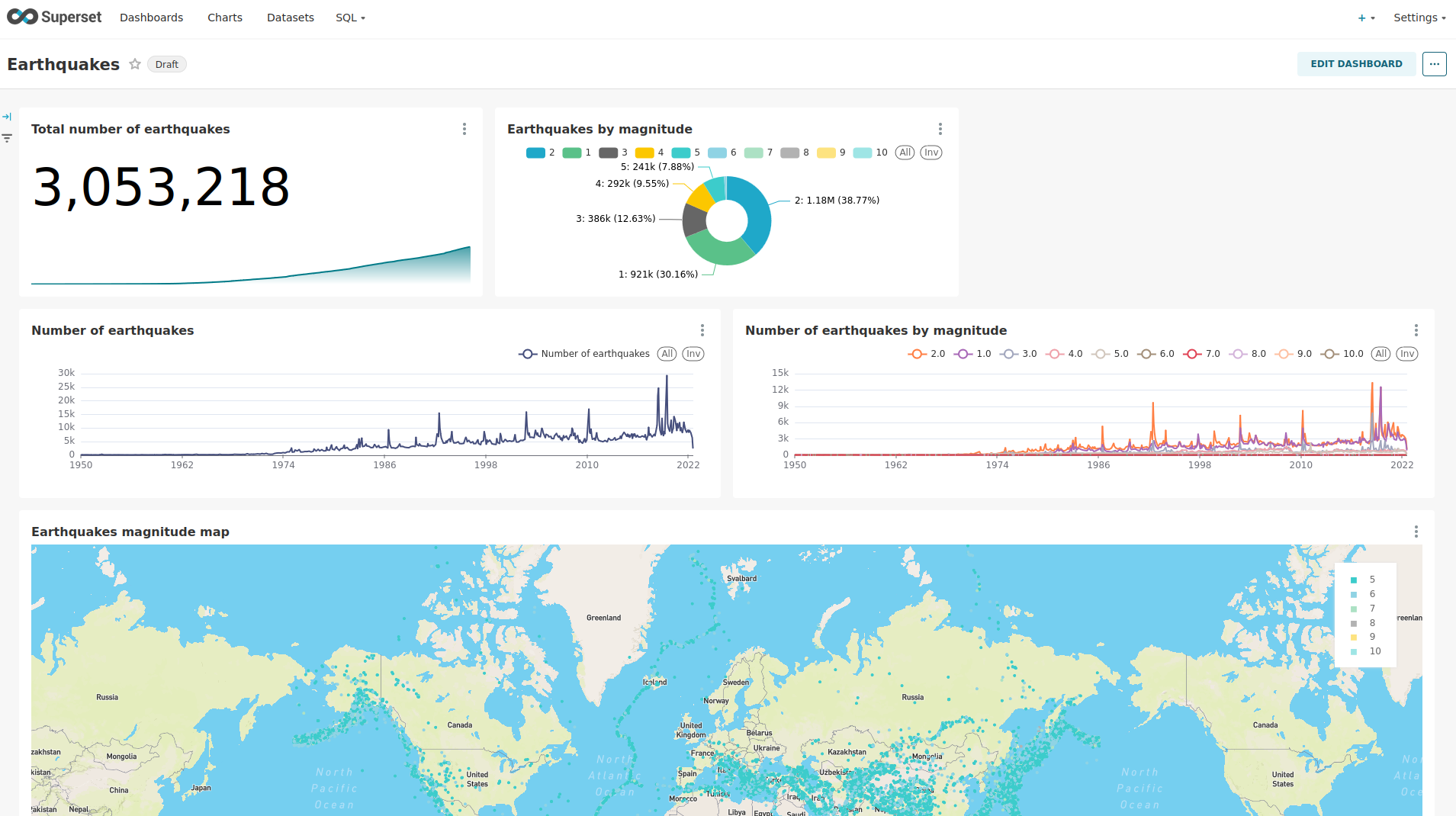
Another dashboard to look at is Earthquakes.
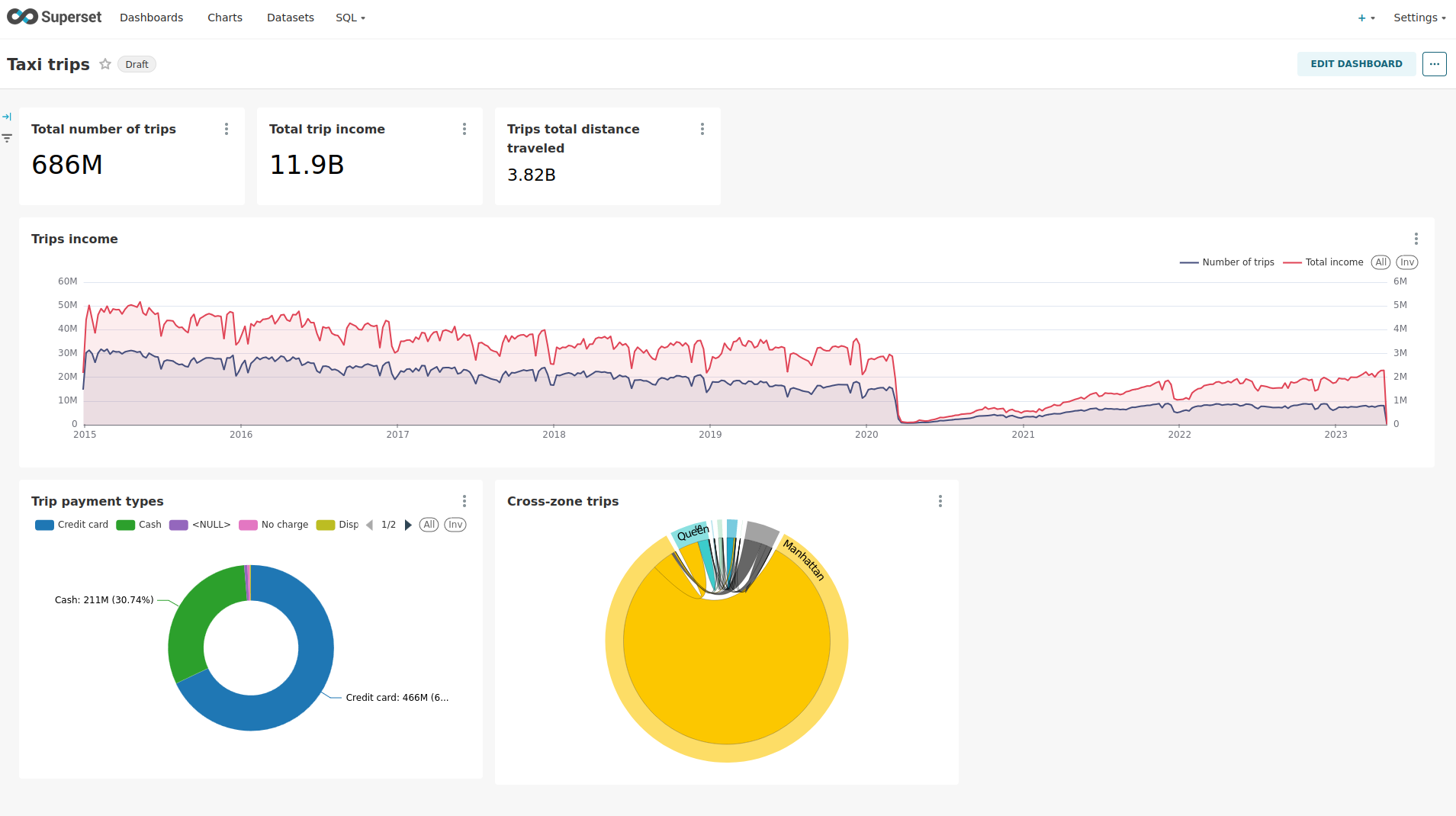
Another dashboard to look at is Taxi trips.
There are multiple other dashboards you can explore on your own.
Viewing Charts
The dashboards consist of multiple charts.
To list the charts, select the Charts tab at the top.
Executing arbitrary SQL statements
Within Superset, you can create dashboards and run arbitrary SQL statements.
On the top click on the tab SQL → SQL Lab.
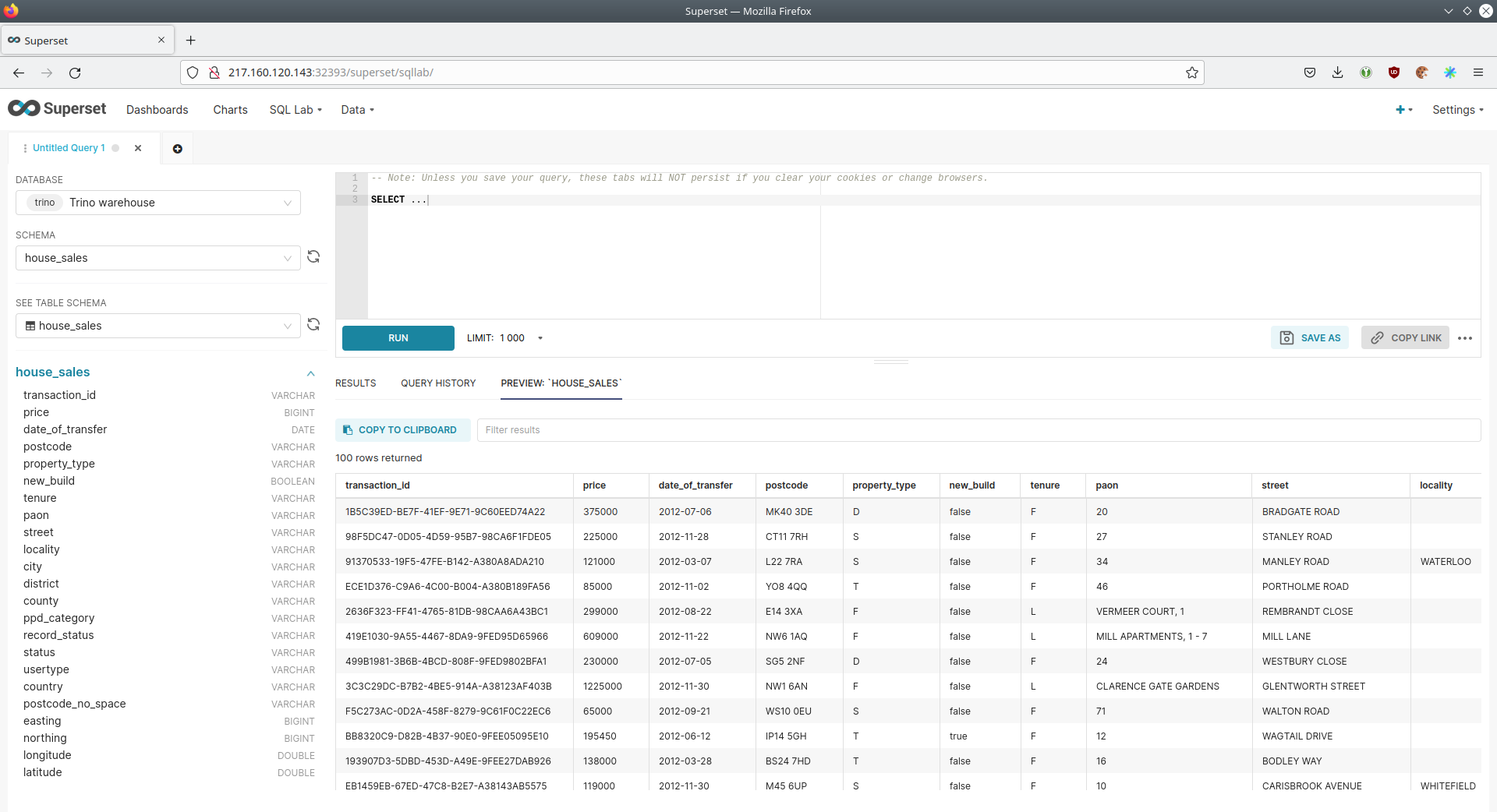
On the left, select the database Trino lakehouse, the schema house_sales, and set See table schema to house_sales.
|
The older screenshot below shows how the table preview would look like. Currently, there is an open issue with previewing trino tables using the Iceberg connector. This doesn’t affect the execution the following execution of the SQL statement. |
In the right textbox, you can enter the desired SQL statement. If you want to avoid making one up, use the following:
select city, sum(price) as sales
from house_sales
group by 1
order by 2 desc