First steps
Once you have followed the steps in the Installation section to install the operator and its dependencies, you will now create a Spark job. Afterwards you can verify that it works by looking at the logs from the driver pod.
Starting a Spark job
A Spark application is made of up three components:
-
Job: this will build a
spark-submitcommand from the resource, passing this to internal spark code together with templates for building the driver and executor pods -
Driver: the driver starts the designated number of executors and removes them when the job is completed.
-
Executor(s): responsible for executing the job itself
Create a SparkApplication:
kubectl apply -f - <<EOF
---
apiVersion: spark.stackable.tech/v1alpha1
kind: SparkApplication
metadata:
name: pyspark-pi
namespace: default
spec:
sparkImage:
productVersion: 3.5.2
mode: cluster
mainApplicationFile: local:///stackable/spark/examples/src/main/python/pi.py
driver:
config:
resources:
cpu:
min: "1"
max: "2"
memory:
limit: "1Gi"
executor:
replicas: 1
config:
resources:
cpu:
min: "1"
max: "2"
memory:
limit: "1Gi"
EOFWhere:
-
metadata.namecontains the name of the SparkApplication -
spec.version: SparkApplication version (1.0). This can be freely set by the users and is added by the operator as label to all workload resources created by the application. -
spec.sparkImage: the image used by the job, driver and executor pods. This can be a custom image built by the user or an official Stackable image. Available official images are listed in the Stackable image registry. -
spec.mode: onlyclusteris currently supported -
spec.mainApplicationFile: the artifact (Java, Scala or Python) that forms the basis of the Spark job. This path is relative to the image, so in this case we are running an example python script (that calculates the value of pi): it is bundled with the Spark code and therefore already present in the job image -
spec.driver: driver-specific settings. -
spec.executor: executor-specific settings.
Verify that it works
As mentioned above, the SparkApplication that has just been created will build a spark-submit command and pass it to the driver Pod, which in turn will create executor Pods that run for the duration of the job before being clean up.
A running process will look like this:
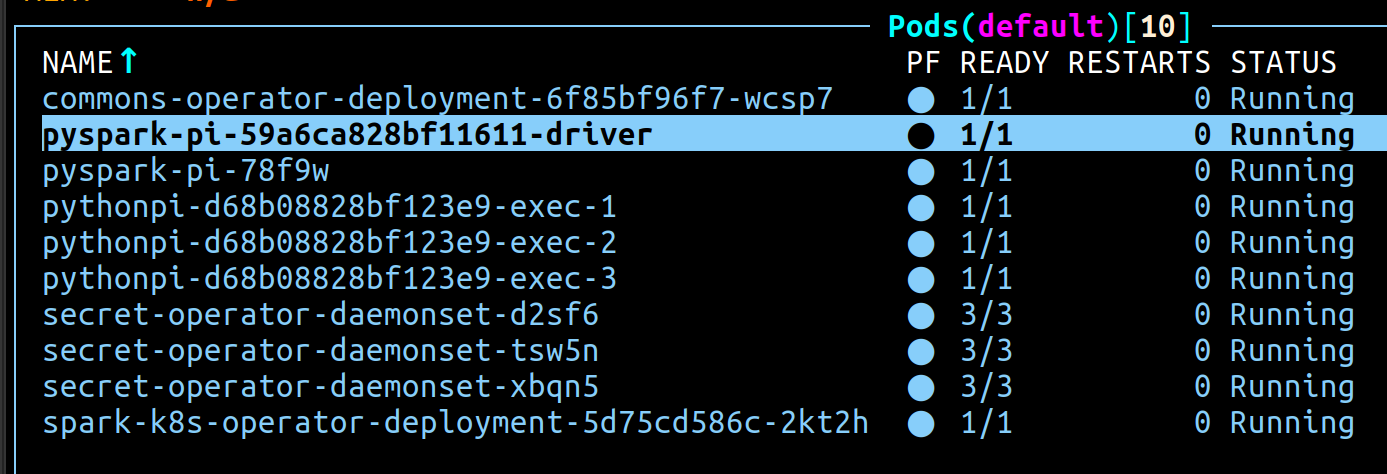
-
pyspark-pi-xxxx: this is the initializing job that creates the spark-submit command (named asmetadata.namewith a unique suffix) -
pyspark-pi-xxxxxxx-driver: the driver pod that drives the execution -
pythonpi-xxxxxxxxx-exec-x: the set of executors started by the driver (in our examplespec.executor.instanceswas set to 3 which is why we have 3 executors)
Job progress can be followed by issuing this command:
kubectl wait pods -l 'job-name=pyspark-pi' \
--for jsonpath='{.status.phase}'=Succeeded \
--timeout 300s
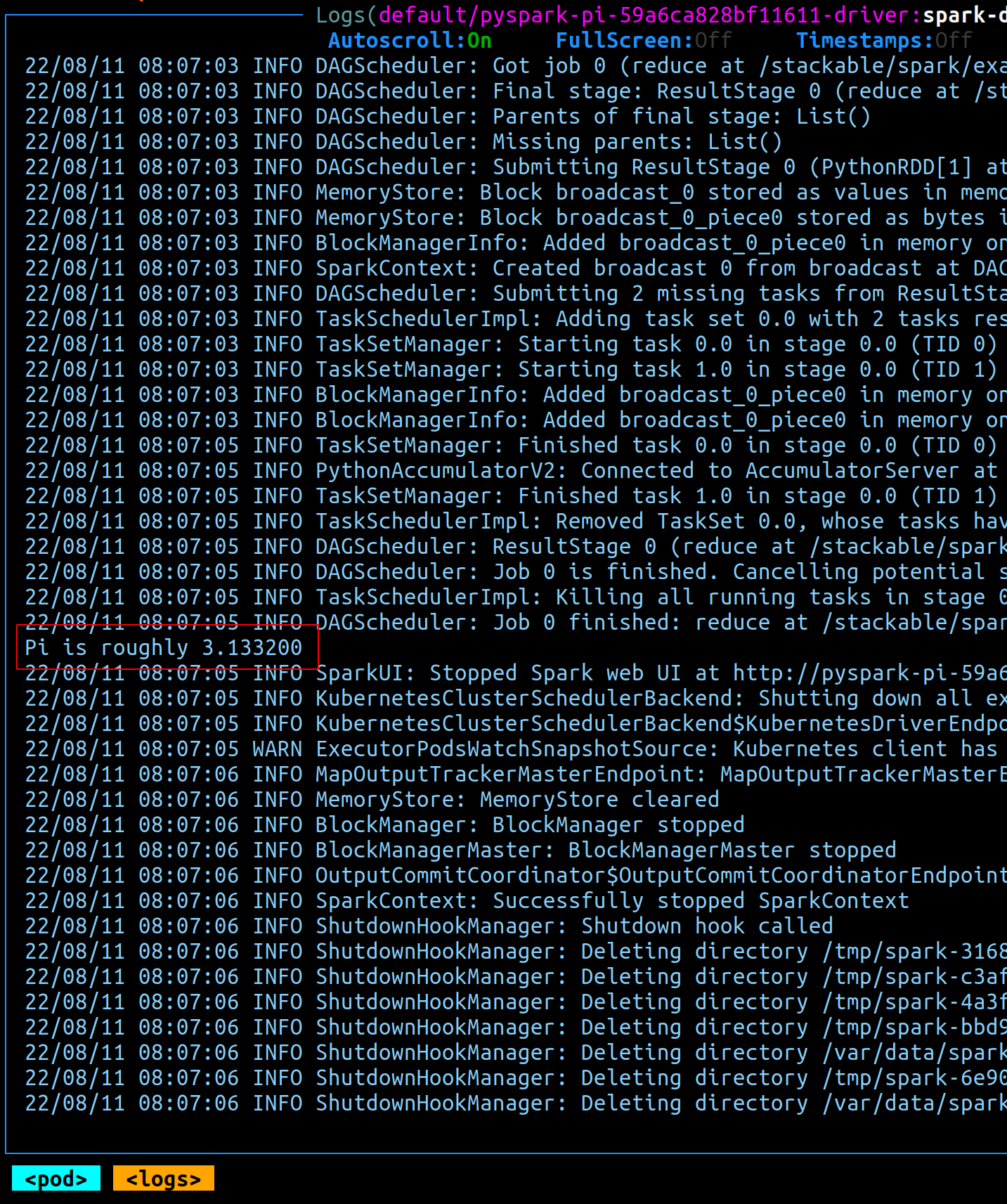
When the job completes the driver cleans up the executor. The initial job is persisted for several minutes before being removed. The completed state will look like this:
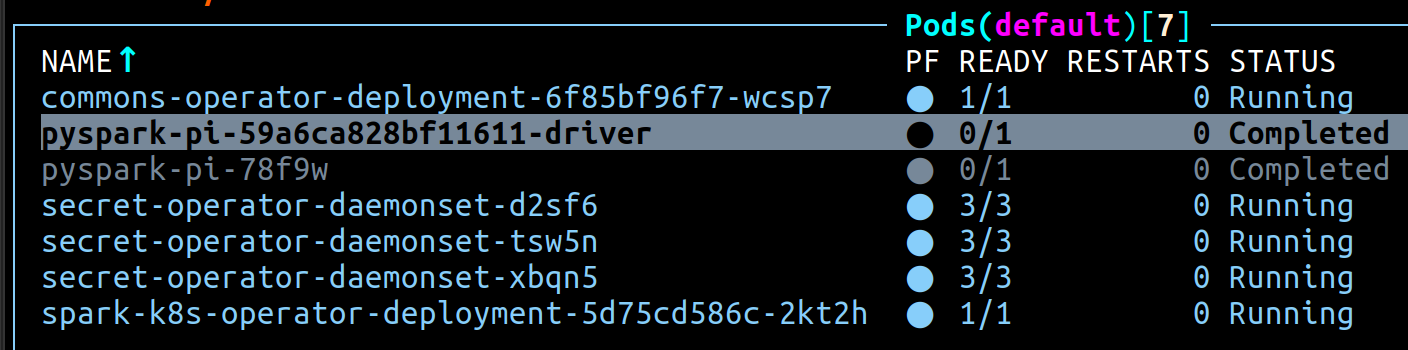
The driver logs can be inspected for more information about the results of the job. In this case we expect to find the results of our (approximate!) pi calculation: